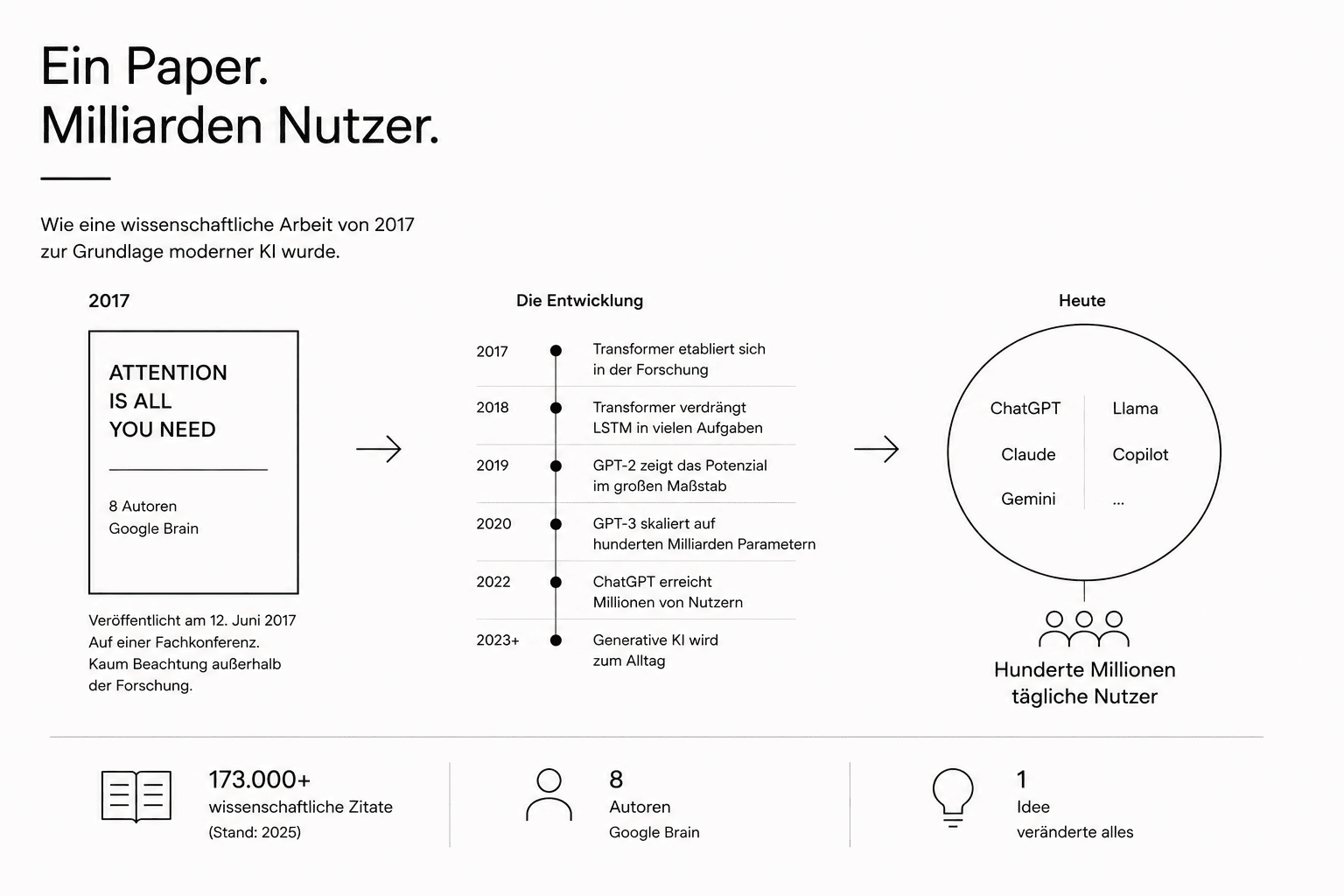
Im Juni 2017 luden acht Forscher bei Google ein Paper auf einen wissenschaftlichen Preprint-Server hoch. Der Titel klang fast wie ein Scherz: "Attention Is All You Need" – Aufmerksamkeit ist alles, was man braucht. Niemand von ihnen hätte vorhergesagt, dass dieses Paper innerhalb weniger Jahre zu einem der meistzitierten wissenschaftlichen Texte des 21. Jahrhunderts werden würde – und zur Grundlage von ChatGPT, Gemini, Claude und praktisch jedem großen Sprachmodell, das heute existiert.
Die Geschichte dieses Papers ist eine Geschichte über ein Problem, das jahrzehntelang als unlösbar galt, eine Lösung, die fast zu einfach klang um wahr zu sein, und acht Menschen, die alle wenig später das Unternehmen verließen, das sie berühmt gemacht hatte.
Das Problem: Sprache ist eine Reihe, kein Haufen
Vor 2017 verarbeiteten die besten KI-Modelle für Sprache – rekurrente neuronale Netze und LSTM-Architekturen – Texte Wort für Wort, in der Reihenfolge, in der sie geschrieben sind. Das klingt naheliegend, hatte aber einen entscheidenden Nachteil: Diese schrittweise Verarbeitung ließ sich kaum parallelisieren. Ein Modell musste Wort eins verstehen, bevor es zu Wort zwei übergehen konnte. Bei langen Texten wurde das langsam – und das Modell "vergaß" oft, was am Anfang eines Satzes stand, bis es am Ende ankam.
Die acht Forscher bei Google Brain und Google Research stellten eine radikale Frage: Was, wenn man die Reihenfolge komplett ignoriert – und stattdessen jedes Wort gleichzeitig mit jedem anderen Wort vergleicht?
Die Idee in einem Satz
Self-Attention lässt jedes Wort in einem Satz "schauen", wie relevant jedes andere Wort für sein eigenes Verständnis ist – alle gleichzeitig, nicht nacheinander. Das Ergebnis lässt sich massiv parallelisieren, was Training auf moderner Hardware drastisch beschleunigt.
Acht Namen, die heute überall stecken
Die Autoren des Papers waren Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Łukasz Kaiser und Illia Polosukhin. Was danach geschah, ist fast so bemerkenswert wie das Paper selbst: Innerhalb weniger Jahre verließ jeder einzelne von ihnen Google – um bei anderen Unternehmen zu arbeiten oder eigene Startups zu gründen. Die Idee war zu groß geworden, um sie in einem einzigen Unternehmen zu halten.
Eine kleine Anekdote zeigt, wie wenig die Tragweite damals absehbar war: Der Name "Transformer" wurde gewählt, weil einer der Autoren, Jakob Uszkoreit, den Klang des Wortes einfach mochte. Ein frühes internes Dokument trug sogar eine Illustration von Charakteren aus dem "Transformers"-Filmfranchise – das Team nannte sich selbst "Team Transformer". Aus diesem Insider-Scherz wurde der Name einer Technologie, die heute Milliarden Menschen täglich nutzen.
Vom Übersetzungs-Tool zur Universalmaschine
Ursprünglich testeten die Forscher ihre Architektur an einer vergleichsweise bescheidenen Aufgabe: maschineller Übersetzung zwischen Englisch und Deutsch. Die Ergebnisse waren gut – aber was die Forscher überraschte, war etwas anderes. Als sie den Transformer auf andere Aufgaben anwandten – etwa das Erzeugen von Wikipedia-artigen Texten – funktionierte er ebenfalls. Und zwar deutlich besser als alles, was es zuvor gab.
Das war der Moment, in dem aus einem Übersetzungswerkzeug eine Universalarchitektur wurde. Innerhalb von etwa zwei Jahren verdrängte der Transformer praktisch alle konkurrierenden Ansätze – LSTM, rekurrente Netze, faltende neuronale Netze für Sprache. Nicht knapp, sondern so deutlich, dass sich das gesamte Forschungsfeld in eine Richtung bewegte.
Eine Zahl, die die Wirkung zeigt
"Attention Is All You Need" wurde mittlerweile über 173.000 Mal zitiert – damit gehört es zu den zehn meistzitierten wissenschaftlichen Arbeiten des gesamten 21. Jahrhunderts, in allen Fachgebieten zusammengenommen.
Eine Idee, die nicht aus dem Nichts kam
So bahnbrechend der Transformer war – er entstand nicht im luftleeren Raum. Die Konzepte von Aufmerksamkeit und Gedächtnis in neuronalen Netzen wurden seit den 1990er Jahren erforscht, unter anderem in der Arbeit zu LSTM von Sepp Hochreiter und Jürgen Schmidhuber, deren 1997 veröffentlichte Architektur über zwei Jahrzehnte lang die dominante Lösung für genau das Problem war, das der Transformer 2017 neu löste.
Das ist ein Muster, das sich durch die gesamte Geschichte der künstlichen Intelligenz zieht: Durchbrüche wirken im Nachhinein wie plötzliche Geniestreiche – tatsächlich stehen sie fast immer auf den Schultern von Arbeiten, die Jahre oder Jahrzehnte zuvor entstanden sind, oft von Forschern, die zu ihrer Zeit kaum Aufmerksamkeit bekamen.
Was 2017 wirklich bedeutet
Wenn Sie heute mit ChatGPT, Claude oder Gemini sprechen, basiert die zugrundeliegende Architektur – mit zahlreichen Weiterentwicklungen – auf jenem Paper von 2017. Acht Forscher, ein Wortspiel als Namensgeber, eine Übersetzungsaufgabe als Testfall – und eine Idee, die binnen weniger Jahre die gesamte KI-Landschaft neu ordnete.
Das ist die eigentliche "stille Revolution": nicht der Moment, in dem ein Chatbot zum ersten Mal mit Menschen spricht – sondern das Paper, das Jahre vorher die Architektur dafür legte, ohne dass es außerhalb der Forschungswelt jemand bemerkte.